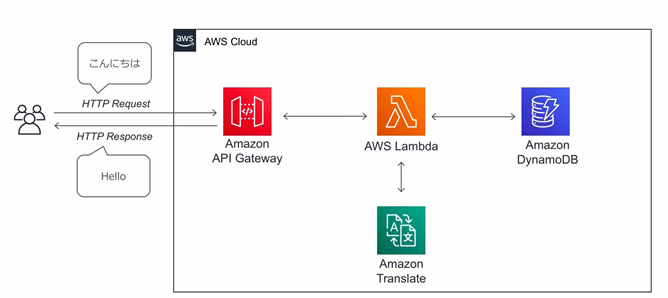
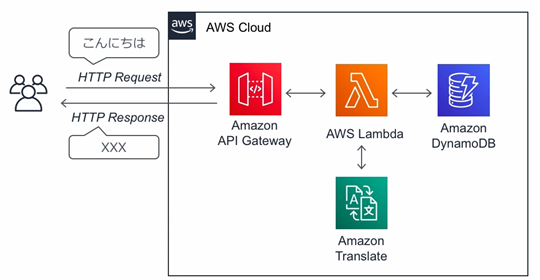
��Lambda���p
�T�[�o���\�[�X���`�����Ɏ����������T�[�r�X�݂̂��`���AAPI�ŌĂяo���ė��p����T�[�r�X�Ƃ���AWS�ł�Lambda������Ă���B
AWS Lambda�ɂ��T�[�o���X�ȃT�[�r�X�Ƃ́F
AWS Lambda�n���Y�I���̓��e�Ɋ�Â��č쐬�B�i���̐���������₷���I�j
https://pages.awscloud.com/event_JAPAN_Hands-on-for-Beginners-Serverless-2019_Contents.html
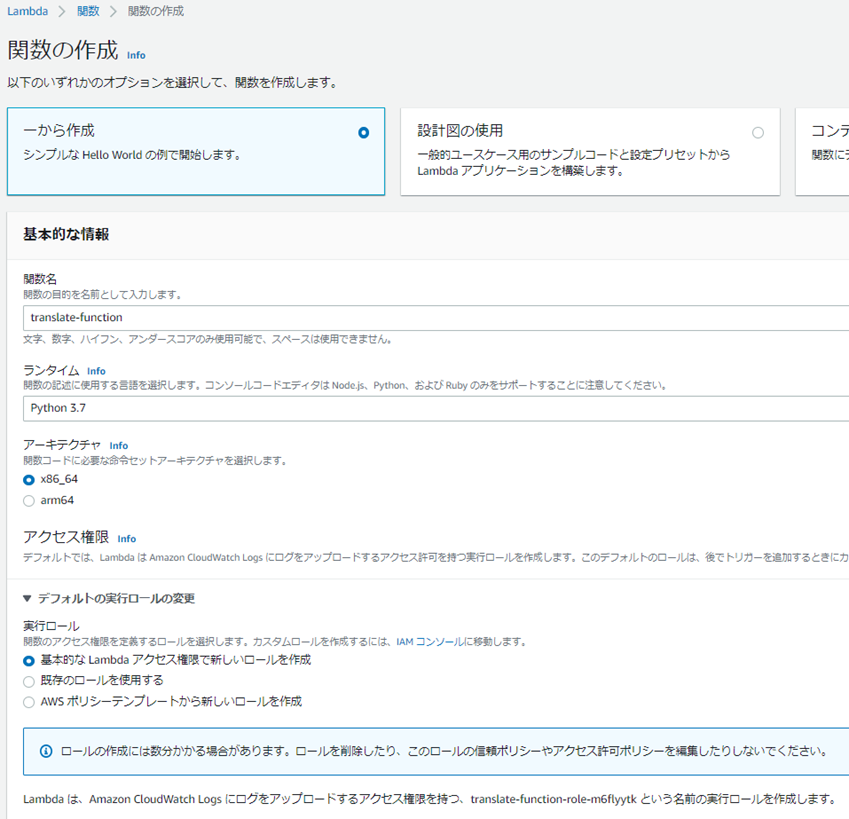
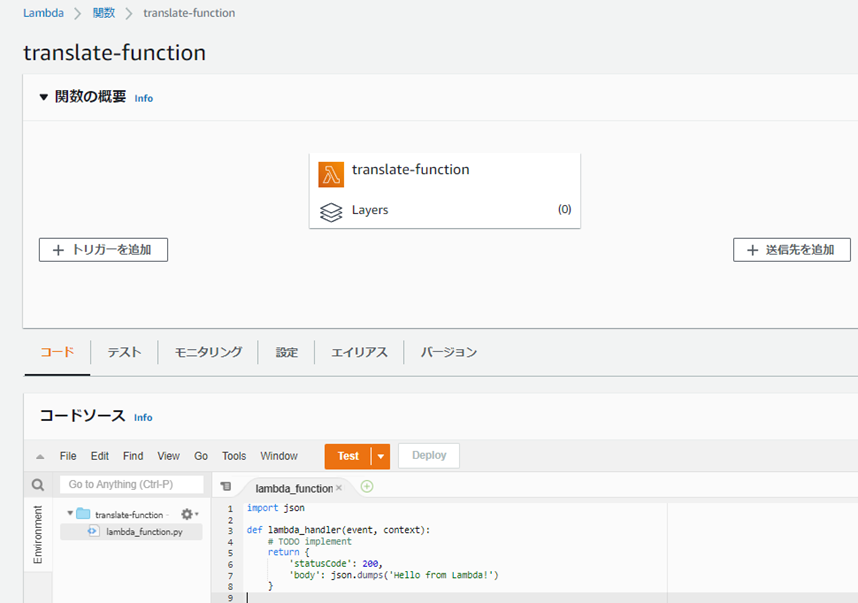
������Ԃ�Lambda���B
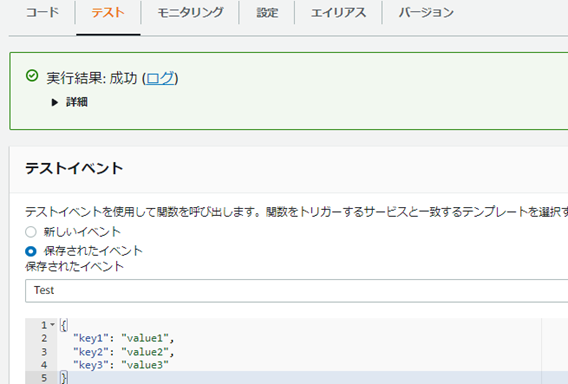
�e�X�g�C�x���g�Ŏ��s
 �v
�v
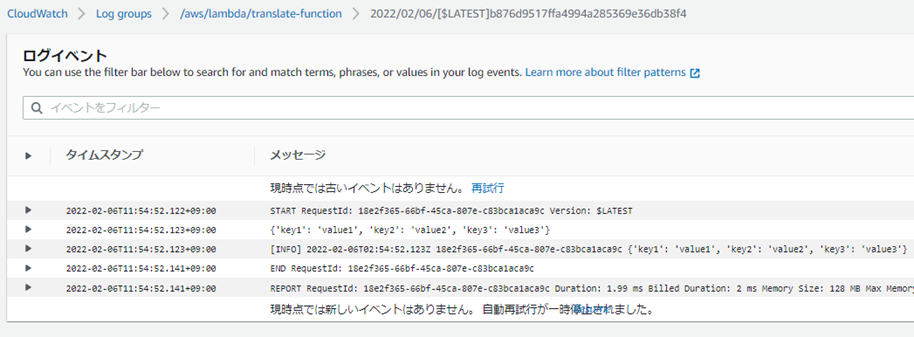
���O�o�͂�lj�����B
print�ŃR���\�[���ւ̏o�͂��\�B
logging�ł�AWS
CloudWatch�ւ̏o�͂��\�B
��Lambda���̃R�[�h�ύX���Deploy���K�v�I
���O��CloudWatch�ɏo�͂���Ă���B
boto3=AWS SDK for
Python�̎g�����F
https://aws.amazon.com/jp/sdk-for-python/
Lambda��Amazon
Translate���Ăяo����悤�ɂ��邽�߂̌�����lj�����ɂ́F
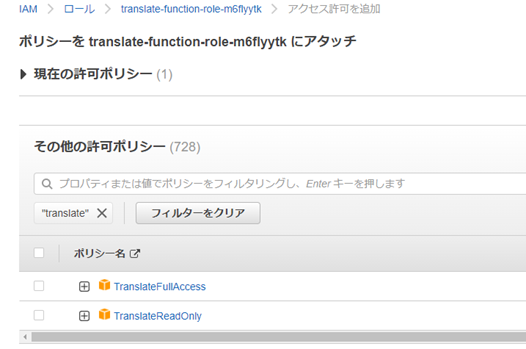
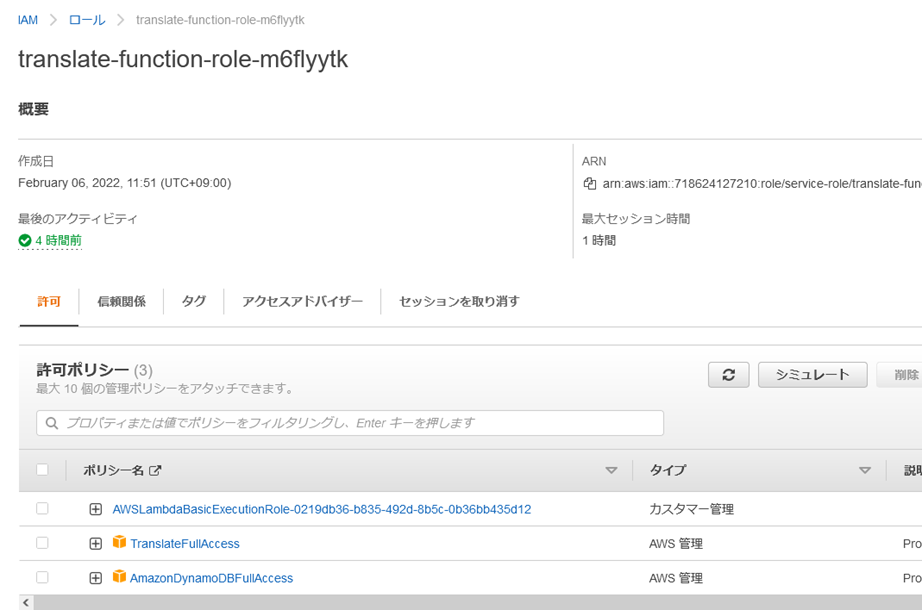
���s���[���̐ݒ��IAM�ŕύX����B
�e�X�g�����I
REST API:
REST�́ARepresentational
State Transfer�̗��B�u��̓I�ɏ�Ԃ��`�������̂����v���K�肷����́B
REST��4�����F
1.
�X�e�[�g�������Ȃ��B�i����肳�����͂��ꎩ�̂Ŋ������ĉ��߂��邱�Ƃ��ł���B�O�̖₢���킹�͊o���Ă��Ȃ��B�������V���v���ɂȂ�j
2.
�����̂��߂̃C���^�[�t�F�[�X�i���\�b�h�j�����ꂳ��Ă���B�iHTTP��GET��POST���\�b�h�Ȃǂ�CRUD����������j
3.
���\�[�X����ӂȎ��ʎq�������A��ӂɎ��ʂ����B�iURI�ȂǂŃ��\�[�X��\������BURI�ɂ͖����݂̂��܂߁A�����͊܂߂Ȃ��j
4.
���̓����ɁA�ʂ̏��₻�̏��̕ʂ̏�Ԃւ̃����N�i�n�C�p�[�����N�j���܂߂邱�Ƃ��ł���B
APIGateway��P�̂Ŏg���ɂ́F
Mock�f�[�^��Ԃ�REST
API���쐬����B
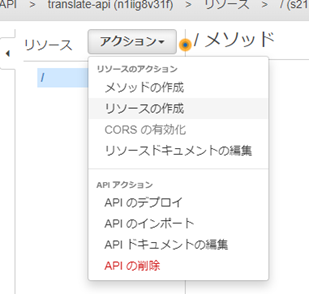
/sample���\�[�X���쐬���AGET���\�b�h���쐬����B
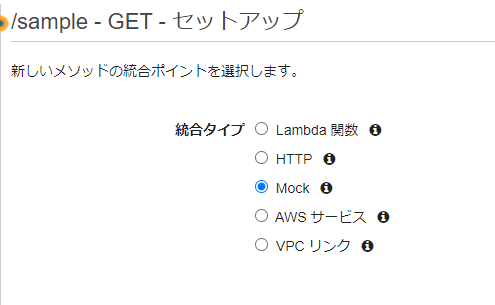
�����^�C�v�ɂ�Mock��I������
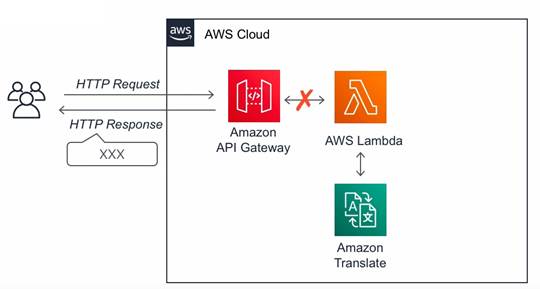
�V����REST��API���쐬����B
/sample���\�[�X���쐬����B
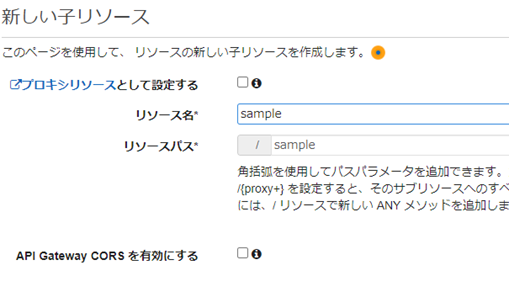
/sample������GET���\�b�h���쐬����B�����^�C�v�ɂ�Mock���w�肷��B
API�̍��i���쐬�����B

�Œ��json��Ԃ����߂ɓ������X�|���X�̐ݒ�������ւ���B
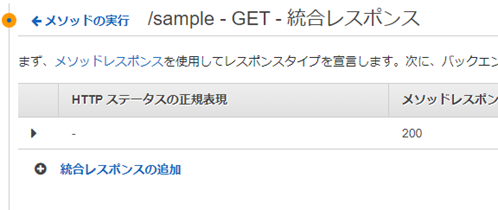
���\�b�h���X�|���X�̐ݒ�Ƀ}�b�s���O�e���v���[�g�Ƃ���application/json��lj�����B
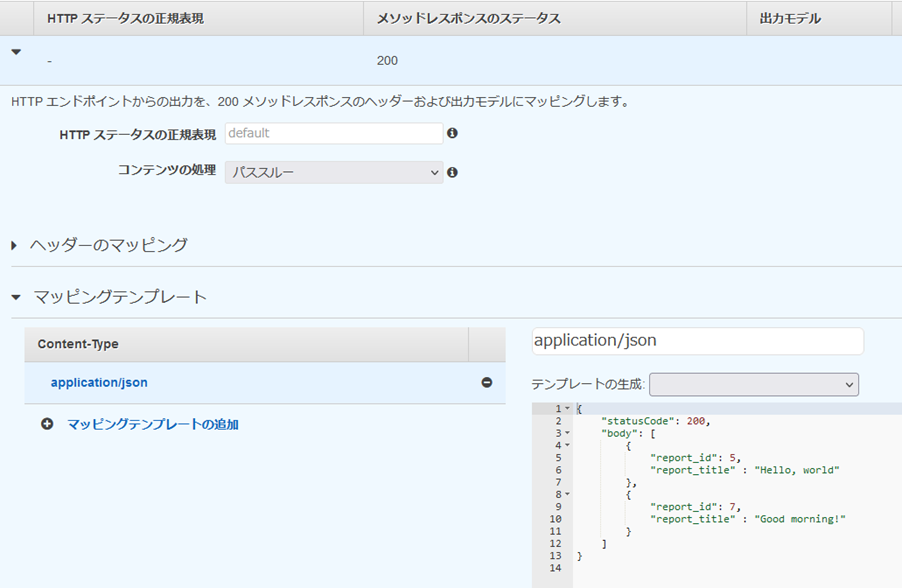
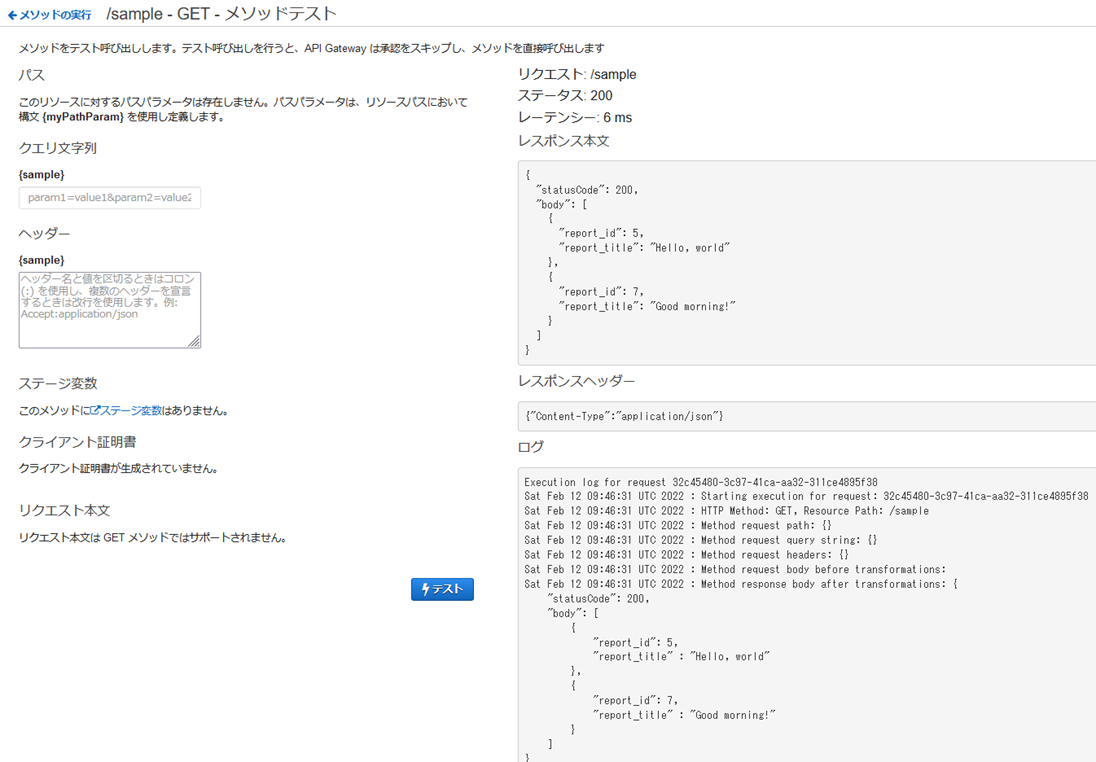
���\�b�h���e�X�g����B
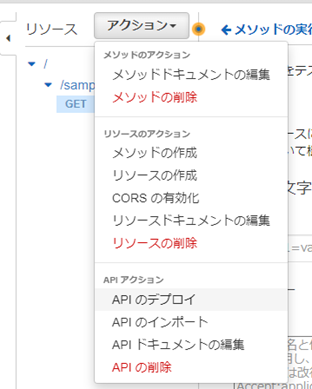
API���f�v���C����B
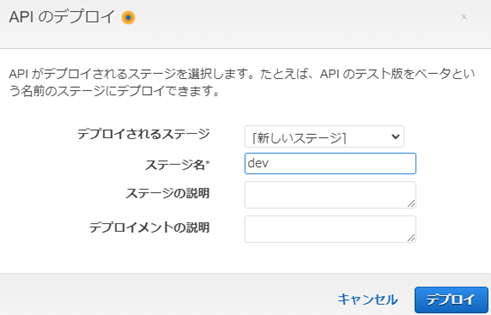
API�̌Ăяo�����\�ƂȂ�B
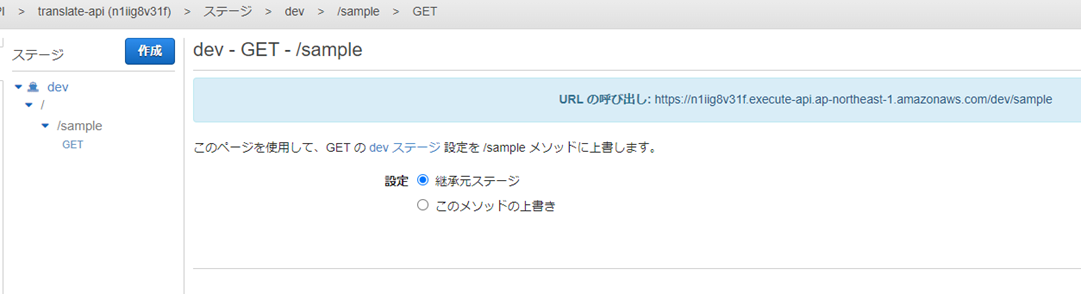
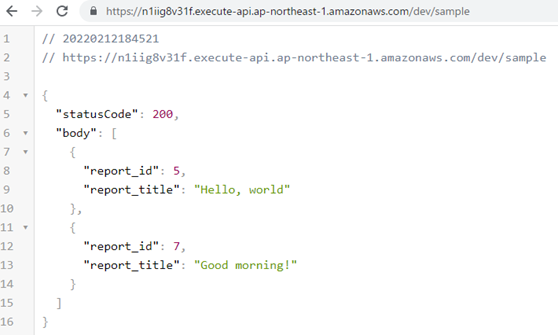
Lambda�������ۂɌĂяo��API Gateway��ݒ肷��ɂ́F
/tranlate���\�[�X��GET���\�b�h�ŌĂяo��
Lambda�v���L�V�����𗘗p���鎖�ŁAinput��output��Lambda�Ƀp�X�X���[����B
����͂܂�A�������N�G�X�g�Ɠ������X�|���X�ł͏������s�킸���\�b�h���N�G�X�g�����̂܂�Lambda�ɓn���ALambda�̖߂�l�����\�b�h���X�|���X�ɂ��̂܂ܓn���Ƃ������B
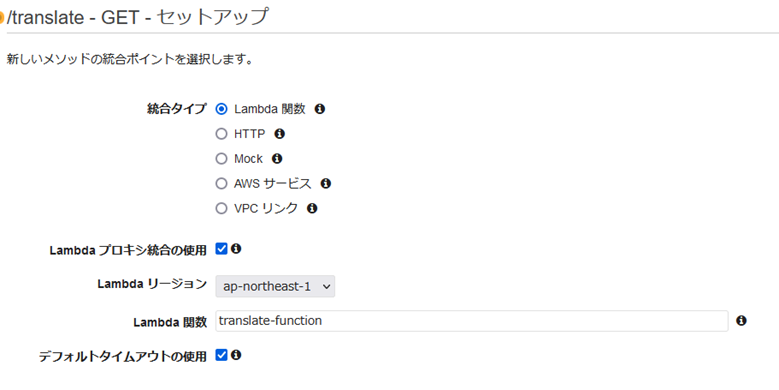
���\�b�h���N�G�X�g�ŃN�G���p�����[�^��ݒ肷��B
�����ł́Ainput_text��K�{�ɂ���B
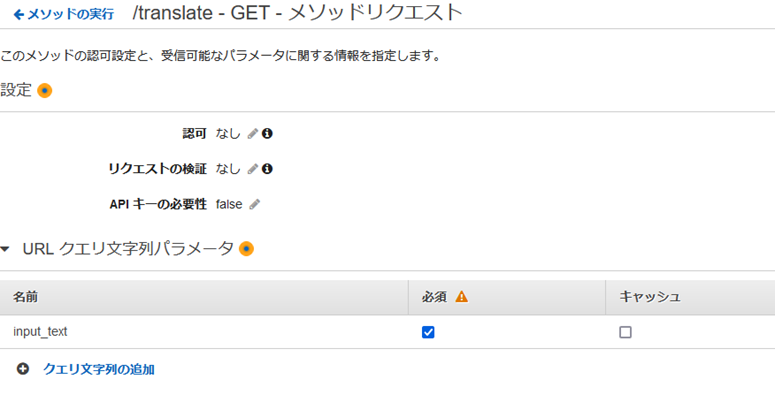
Lambda����ҏW����BAPIGateway���������X�|���X�ł��邽�߁AAPIGateway�̃��[���ɏ]���A�߂�l���`����B
�߂�l�̃��[���F
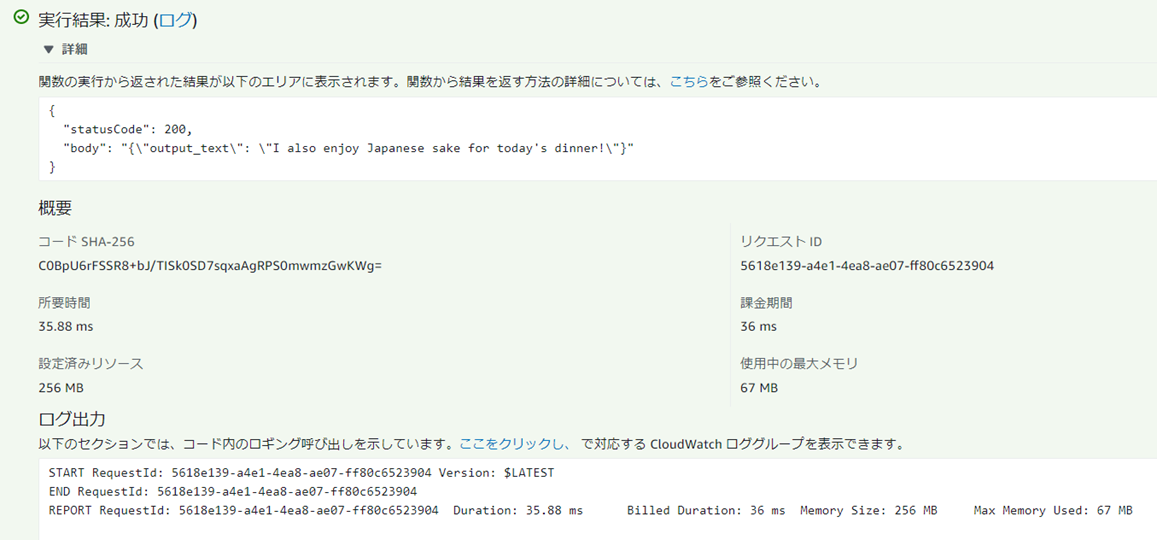
{
statusCode: "...",
// a valid HTTP status code
headers: {
custom-header: "..." // any API-specific
custom header
},
body: "...",
// a JSON string.
isBase64Encoded:
true|false // for binary
support
}
����L4���ڂ͕K�{�B
APIGateway��AWS
Proxy��p���ăe�X�g�C�x���g���쐬����B
queryStringParameters��input_text�ɖ|��Ώۂ̕�������e�X�g�p�Ɏw�肵�Ă���B
{
"body": "eyJ0ZXN0IjoiYm9keSJ9",
"resource": "/{proxy+}",
"path": "/path/to/resource",
"httpMethod": "POST",
"isBase64Encoded": true,
"queryStringParameters": {
"input_text": "���{�����݂����I"
},
"multiValueQueryStringParameters": {
"foo": [
"bar"
]
},
URL�ɕK�{�p�����^��lj����ăA�N�Z�X����B

DynamoDB�̓����F
NonSQL�̃f�[�^�x�[�X�B
�EPrimaryKey�F��L�[�BItem����ӂɎ��ʂ���L�[�BPartitionKey�ƃ\�[�g�̂��߂̗v�f�ł���SortKey�ō\�������B�iPartitionKey�݂̂ł�PrimaryKey���\�����邱�Ƃ͉\�jPartitionKey��SortKey�̑g��������ӂł����Item��o�^���鎖���o����B
�EItem�F��L�[���Ƃ̍��ځBRDB�ł̍s�ɑ�������B
�EAttribute�F�eItem�ɏ������鑮���BPrimaryKey�ȊO�͕s�����ł����Ă����Ȃ��B
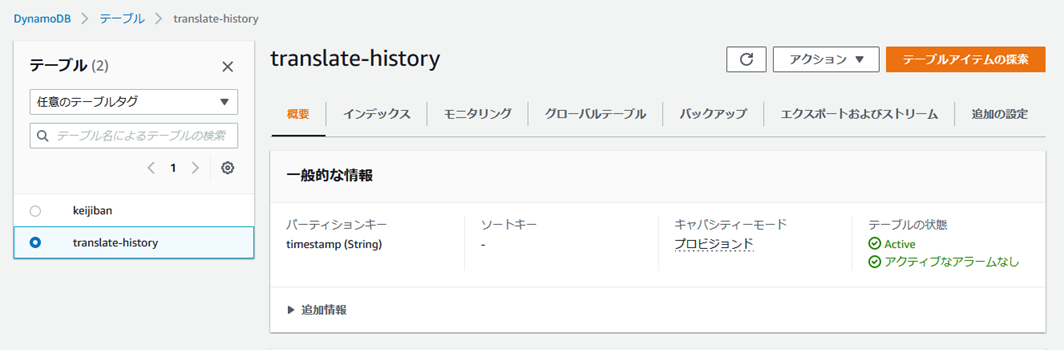
DynamoDB�Ɛڑ�����ɂ́F
�e�[�u���̐ݒ�B
IAM��DynamoDB�ւ̓ǂݏ���������lj��B
��AWS Server Application Model (SAM)��p���ăT�[�o���X���������\�z����
�n���Y�I���V���[�Y�̑��e�F
https://pages.awscloud.com/event_JAPAN_Ondemand_Hands-on-for-Beginners-Serverless-2_CP.html
�܂��ACloud9�����쐬����B
Cloud9���̍\�����B�B�B
Cloud9�̊��쐬�����B
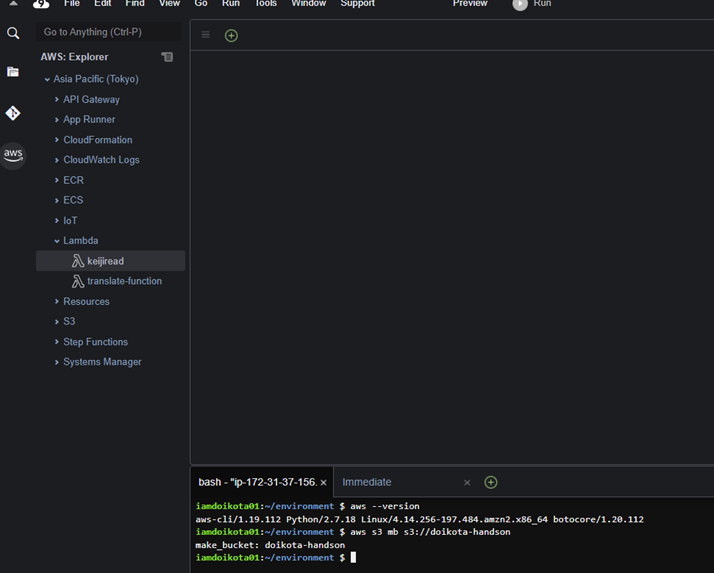
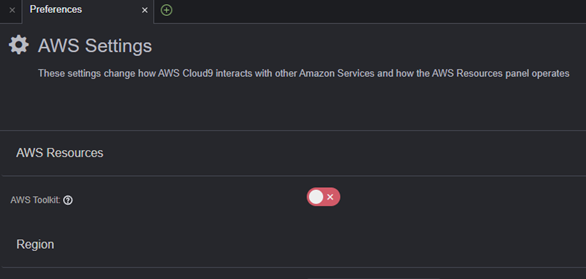
�I�}�P�jCloud9�̉E�[�ɂ���AWS Resources�̕\���E��\�����ւ���
Cloud9����SAM�𗘗p����Lambda���J������ɂ́F
�܂��As3��Lambda�̃o�C�i�����i�[���邽�߂̐V�����o�P�b�g����������B
$ aws s3 mb
s3://doikota-handson
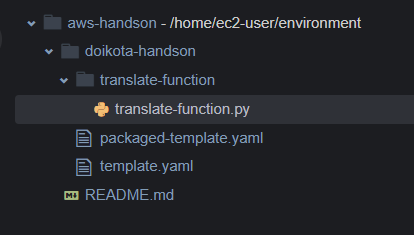
Cloud9��Ƀ����_���̃\�[�X�R�[�h�itranslate-function.py�j�ƃe���v���[�g�t�@�C���itemplate.yaml�j���쐬����B
�ڕW�Ƃ���t�@�C���\���F
��packaged-template.yaml��aws
package�R�}���h���쐬����B
CloudFormation�p�Ƀp�b�P�[�W����B
aws
cloudformation package --template-file template.yaml --s3-bucket
doikota-handson --output-template-file packaged-template.yaml
packaged-template.yaml�������B
CloudFormation��Lambda���\�[�X���f�v���C����B
aws
cloudformation deploy --template-file
/home/ec2-user/environment/doikota-handson/packaged-template.yaml
--stack-name=doikota-handson --capabilities=CAPABILITY_IAM
�e�X�g���{�����I
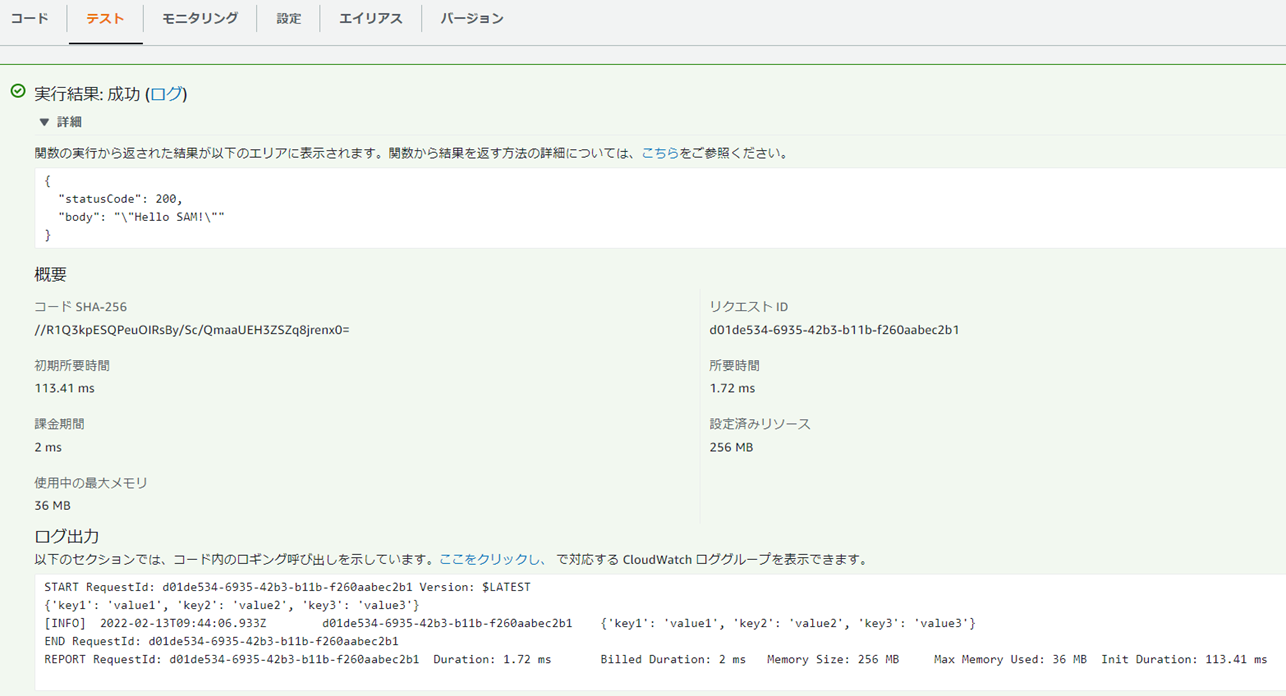
SAM���g����Amazon
Translate�ƘA�g������ɂ́F
�p�b�P�[�W�A�f�v���C����B
$ aws
cloudformation package --template-file template.yaml --s3-bucket
doikota-handson --output-template-file packaged-template.yaml
$ aws
cloudformation deploy --template-file
/home/ec2-user/environment/doikota-handson/packaged-template.yaml
--stack-name=doikota-handson --capabilities=CAPABILITY_IAM
Lambda���Q�Ƃ�����s���[����TranslateFullAccess�̃|���V�[���lj�����Ă���B
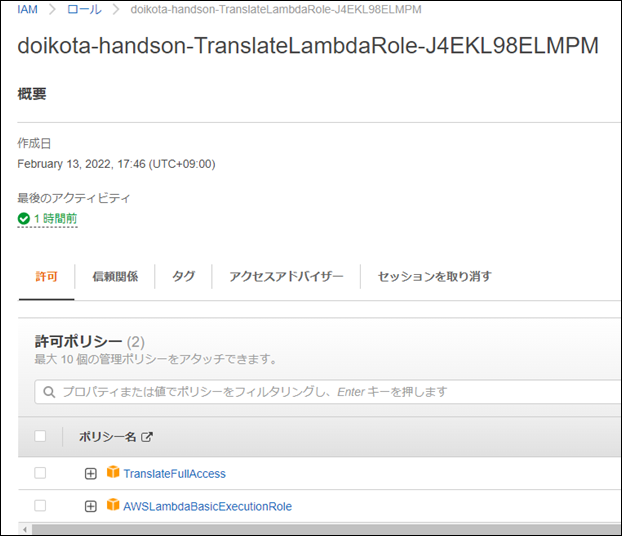
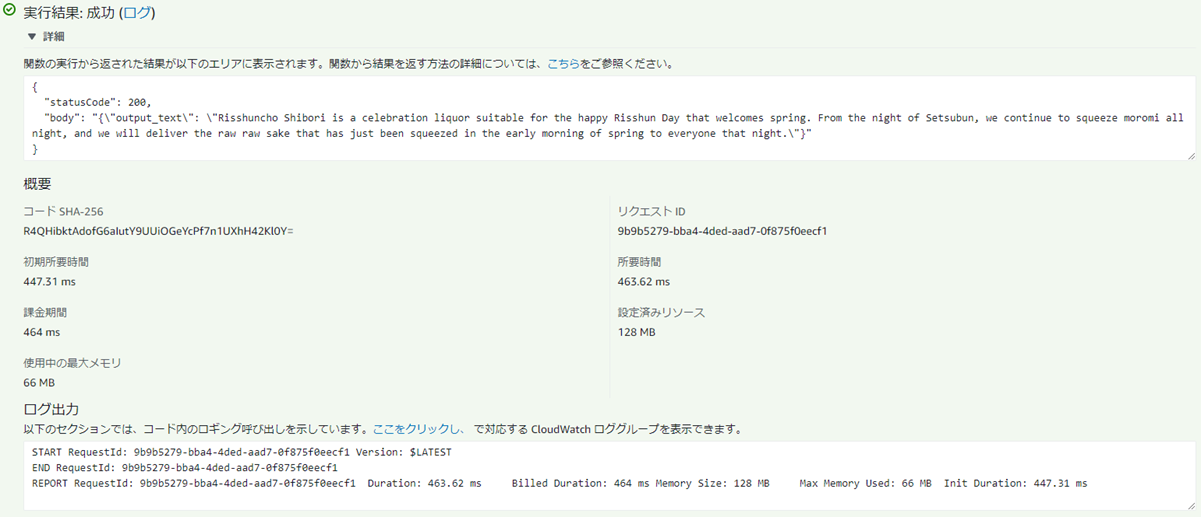
�e�X�g�����I
SAM���g����APIGateway�ƘA�g������ɂ́F
���n���Y�I���̃\�[�X�R�[�h�Q�ƁB
�p�b�P�[�W�A�f�v���C����B
$ aws
cloudformation package --template-file template.yaml --s3-bucket
doikota-handson --output-template-file packaged-template.yaml
$ aws
cloudformation deploy --template-file
/home/ec2-user/environment/doikota-handson/packaged-template.yaml
--stack-name=doikota-handson --capabilities=CAPABILITY_IAM
�I�}�P�@SAM
CLI�F
SAM�\���̏�������Ԃ��쐬����B
$ sam init
�쐬���ꂽSAM�\�����A�������\������������B
$ sam validate
���[�J�����Ńr���h����B
$ sam build
AWS���Ƀf�v���C����B
$ sam deploy
���̎��_�ŁAAWS���Lambda�̎��s��API�̌Ăяo�����\�ƂȂ��Ă���B
���[�J����lambda���̑҂����J�n����B
$ sam local
start-lambda
���[�J����lambda�����Ăяo���B
$ aws lambda
invoke --function-name "HelloWorldFunction" --endpoint-url
"http://127.0.0.1:3001" --no-verify-ssl out.txt
{
"StatusCode": 200
}
out.txt�ɖ߂�l���������܂��B
$ more out.txt
{"statusCode":
200, "body": "{\"message\": \"hello world
2022/02/26 03:33:15\"}"}
���[�J����invoke����B
$ sam local
invoke
Invoking
app.lambda_handler (python3.7)
Skip pulling
image and use local one:
public.ecr.aws/sam/emulation-python3.7:rapid-1.33.0-x86_64.
Mounting
/home/ec2-user/environment/sam-app/.aws-sam/build/HelloWorldFunction as
/var/task:ro,delegated inside runtime container
END RequestId:
a6557c76-eb80-4f4c-8c39-69eb7ab4d233
REPORT
RequestId: a6557c76-eb80-4f4c-8c39-69eb7ab4d233 Init Duration: 1.44 ms Duration: 90.56 ms Billed Duration:
91 ms Memory Size: 128
MB Max Memory
Used: 128 MB
{"statusCode":
200, "body": "{\"message\": \"hello world
22/02/26 03:58:41\"}"}
���[�J����APIGateway�̑҂����J�n����B
$ sam local
start-api
���[�J����API�̌Ăяo��������B
$ curl
http://127.0.0.1:3000/hello
{"message":
"hello world 22/02/26 06:38:15"}
translate�ł�SAM���g�����B
$ sam validate
$ sam build
$ sam local
invoke -e event.json
$ sam deploy
--stack-name=doikota-handson --s3-bucket doikota-handson
--capabilities=CAPABILITY_IAM
��AWS Lambda��AWS AI�T�[�r�X�̑g�ݍ��킹
https://pages.awscloud.com/event_JAPAN_Ondemand_Hands-on-for-Beginners-Serverless-3_CP.html
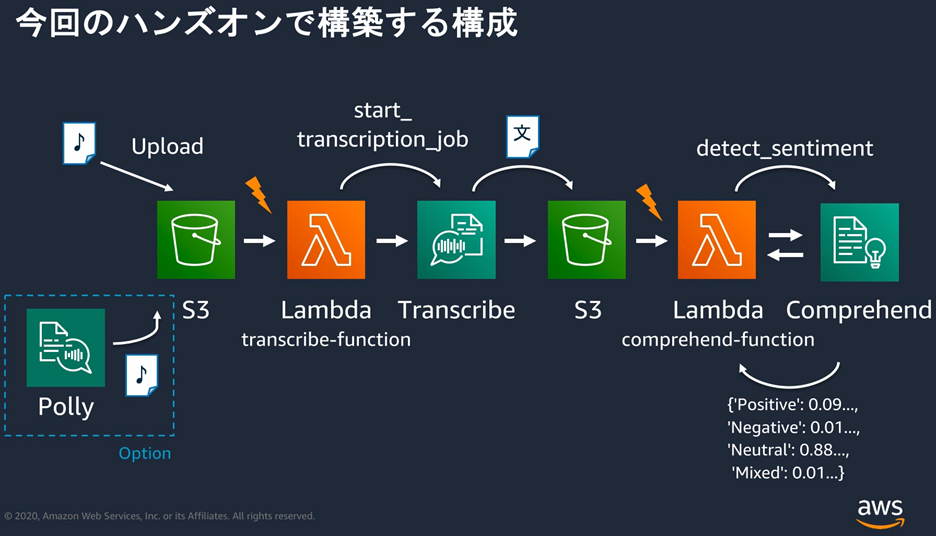
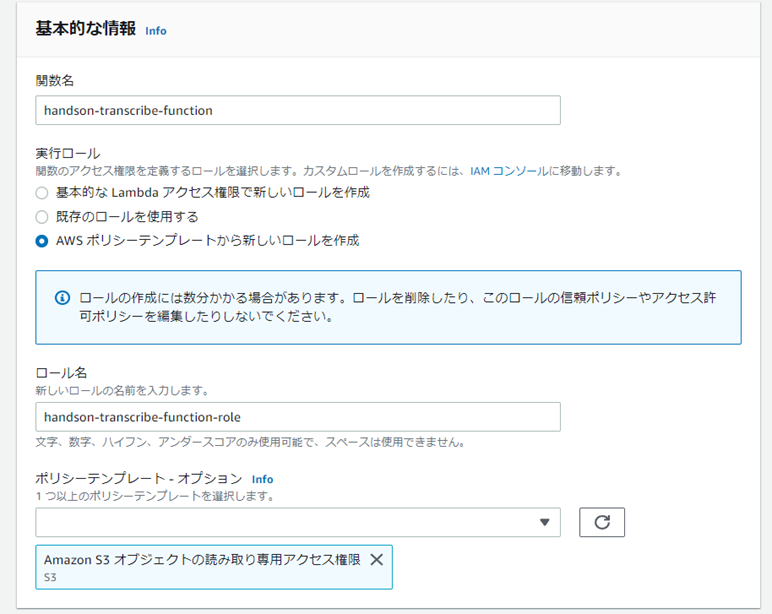
Blueprint�i�v�}�j���g���āALambda�����쐬�B
���j�u���s���[����AWS�|���V�[�e���v���[�g����V�������[�����쐬�v��I�Ȃ��Ɗ��쐬�����܂������Ȃ������B�i��{�I�ȁc���Ɗ��쐬���ɃC�x���g�쐬�̃G���[���o���j
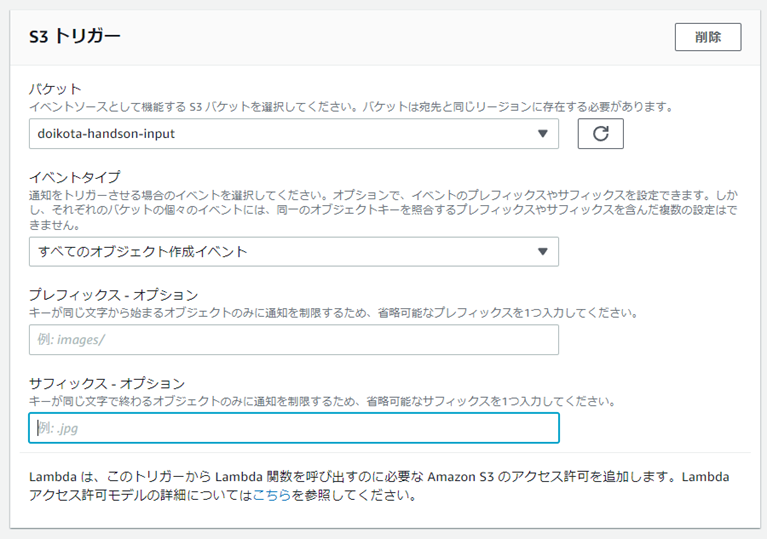
���쐬��AS3����̃g���K�[���쐬�����̂��ȉ��B
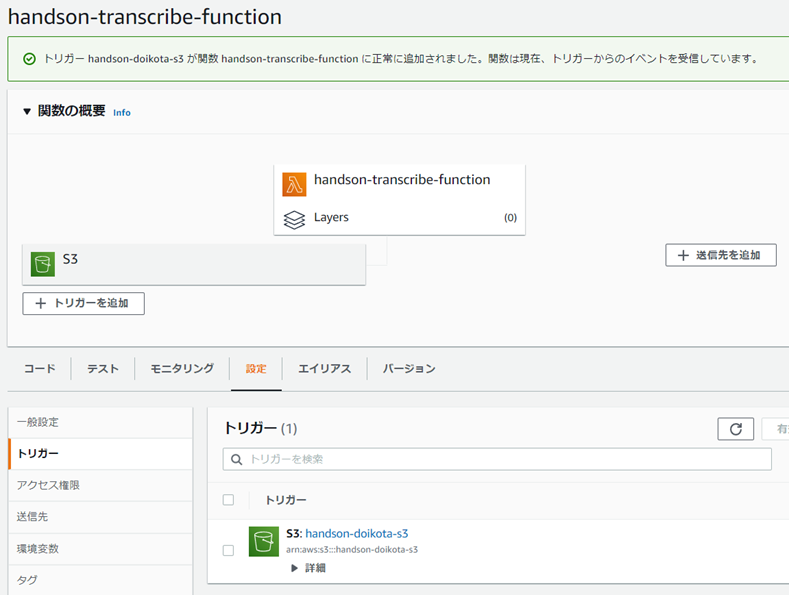
Transcribe�ʼn������N�������s���A�e�L�X�g�t�@�C����S3�ɕۑ�����B
Name�FTest-Job
Language�FJapanese
Input Data�Fs3://handson-doikota-s3/h4b-serverless-3.mp3
Output data�Fs3://handson-doikota-s3-output
Comprehend�FAI�Ńe�L�X�g�̓��e�̊���x����Ԃ��T�[�r�X
Polly�F�e�L�X�g�������ɕϊ�����T�[�r�X
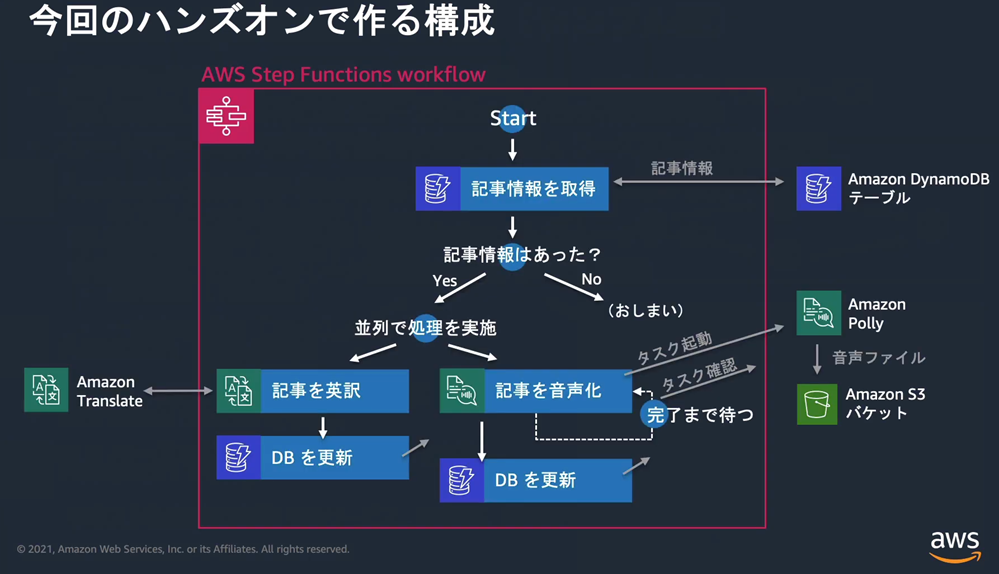
��AWS Step Functions ����
�r�W���A���c�[�����g���ă��[�R�[�h�Ƀ��[�N�t���[���쐬����
InputPath�A�p�����[�^�A����� ResultSelector�F
https://docs.aws.amazon.com/ja_jp/step-functions/latest/dg/input-output-inputpath-params.html
�㗬���痬��Ă���JSON���b�Z�[�W�̂��鍀�ڂ̒l���g�������ꍇ�AResultSelector���g���B�h$.���鍀�ځh�Ƃ�����̂��鍀�ڂ̒l���擾�ł���B
�܂��A��L��$.���鍀�ڂ��㑱�ɗ��������ꍇ�ɂ́A�h�w�肵��������.$�h�Ƃ��č��ږ����`����B
��j
{
"result1.$":
"$.Payload.key1",
"result2.$":
"$.Payload.key2",
"result3.$":
"$.Payload.key3"
}
Payload�Ƃ́ALambda�n���h�����߂�l��StepFunction�ɓn���Ƃ��ɖ߂�l�̓��e���l�߂�v�f���ŁALambda�n���h������return�Ŏw�肳�ꂽ�f�[�^�͂���������o���B
AWS Step Functions��Input/Output��R�����Ă݂�F
https://zenn.dev/ken_11/articles/4c61683629f45f
Lambda
Invoke�Ń����_��JSON��n���ALambda���Œl�����o���Ă����return����ƁA���̃X�e�b�v�̃X�e�b�v�o�͂�return�������e���o�͂����B
Step Functions�̕ϐ��v�f�F
�E���͐���FInputPath
�E�o�͐���FOutputPath
�E���ʐ���FResultSelector�AResultPath
InputPath�́A���̃X�e�b�v�ɓn��������$.�ȉ��Ŏw�肵��JSON�p�X�݂̂ɍi��d�g�݁B�i$.�̓��[�g���Ӗ�����j
OutputPath�́A���̃X�e�b�v����Ԃ��߂�l��$.�ȉ��Ŏw�肵��JSON�p�X�݂̂ɍi��d�g�݁B
ReusltSelector�́A�o�͑O�Ɍ��ʂ��ĕҏW���邱�Ƃ��o����d�g�݁B
ResultPath��1�ڂ̋@�\�́A�X�e�b�v���͂����̂܂܃X�e�b�v�o�͂ɂ��邱�ƁB
JSONPath Online Evaluator - jsonpath.com�F
JSONPath Syntax�F
https://support.smartbear.com/alertsite/docs/monitors/api/endpoint/jsonpath.html
�E�h�b�g�\���ƃJ�b�R�\���͖{���I�ɓ����B
�E$�̓��[�g�i��ԍŏ��̒��J�b�R�j���w���B
�E@�͌��݂̃m�[�h���w���B
�E..�L�[���w�肷��ƁA���̃L�[�����܂ޗv�f���ׂĂ����o�����i���x���ɊW�Ȃ��j�B
�E*�Ń��C���h�J�[�h�w�肪�o����B
�E[]�ŃC���f�b�N�X�w�肪�ł���B[0:3]�ȂǂŃC���f�b�N�X0�Ԃ���3�Ԗڂ܂łȂǎw��ł���B[0:][:3]�Ȃǂ��B[-3:]�ōŌ��3�v�f�B
�E?�ɂ��t�B���^�[�@�\�͔z��ɂ����g���Ȃ��B[?(@.�L�[)]�ȂǂƂ��Ďg���B
�E?�̌��()�ɂ́A�_����(@.�L�[) �ŃL�[�����݂���v�f��A�_����(@.�L�[==�f�l�f)�ŃL�[�ƒl����v����v�f�̒��o���s����B
JSON�ǂݍ��݁A�ϊ��A�������݁F
JSON�̊�{�����PyCharm��ł����炢���Ă����B
jsontest.py
import json
import copy
from datetime import datetime, timedelta
from pytz import timezone
# JSON�ǂݍ���
with open('sample.json', 'r') as file:
# �t�@�C�����玫���^��
js1 = json.load(file)
# �ʕϐ��ɐ[���R�s�[�i�Q�ƂȂ��j
js2 = copy.deepcopy(js1)
# JSON��������
js2['key1'] = "Hello " + js1['key1']
js2['key2'] = (js1['key2'] + 2) * 2
# �������͂�datetime�^��
t2 = datetime.strptime(js1['key3'], "%Y-%m-%dT%H:%M:%S.%f")
# �^�C���]�[���w��i���̎�����naive�̏ꍇ�Aaware�ɂ���j
t2 = t2.astimezone(timezone('Asia/Tokyo'))
# �^�C���]�[���ϊ��i���̎������x�[�X�ɕʂ̃^�C���]�[���ł̎����\���ɐ�ւ�����j
# t2 = t2.astimezone(timezone('UTC'))
# ���t��1���J��グ��
t2 = t2 + timedelta(days=1)
js2['key3'] = t2.strftime("%Y-%m-%dT%H:%M:%S.%f%z")
# JSON��������
with open('result.json', 'w') as file:
json.dump(js2, file, indent=2, ensure_ascii=False)
sample.json
{
"key1": "value1",
"key2": 100,
"key3": "2022-05-04T09:08:34.123000"
}
result.json
{
"key1": "Hello value1",
"key2": 204,
"key3": "2022-05-05T09:08:34.123000+0900"
}
��L�\�[�X��Lambda�Ŏg����悤�ɂ���ɂ́Apytz��Lambda���s���ɃA�b�v���[�h����K�v������B
�Q�l�j
https://www.playfulit.net/articles/2019/01/28/aws-lambda-no-module-named-pytz-error/
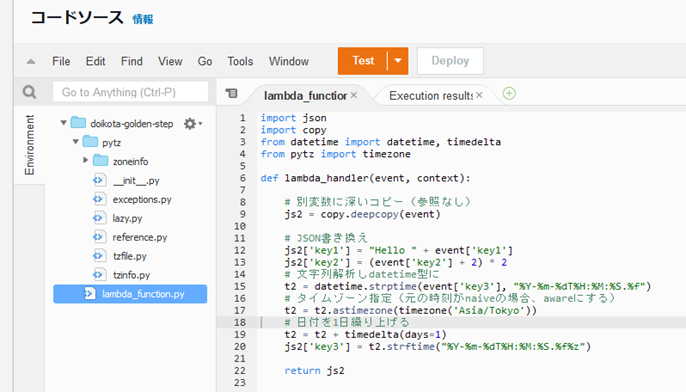
�A�b�v���[�h�O��pytz��lambda_function.py��\�߃��[�J����PC�Ƀ_�E�����[�h���Azip���Ă����B
$ py
-m pip install pytz -t .
py�v���O�����ɂ��A-m�w��̂��߃X�N���v�g���s���s���B�Ώۂ�pip�ŁApip�̓C���X�g�[����pytz���C�u�����ɑ��čs���B-t�ɂ��ꏊ�w�肪�s���āA�u.�v���Ȃ킿�J�����g�f�B���N�g���B
Lambda�����zip���A�b�v���[�h����ƁAzip�̒��g���𓀂���S�ēW�J�����Ɠ����ɁA����܂ŕۑ�����Ă����t�@�C���͂��ׂď����Ă��܂��̂ŗv���ӁB
StepFunction���ReusltSelector���w�肷��B
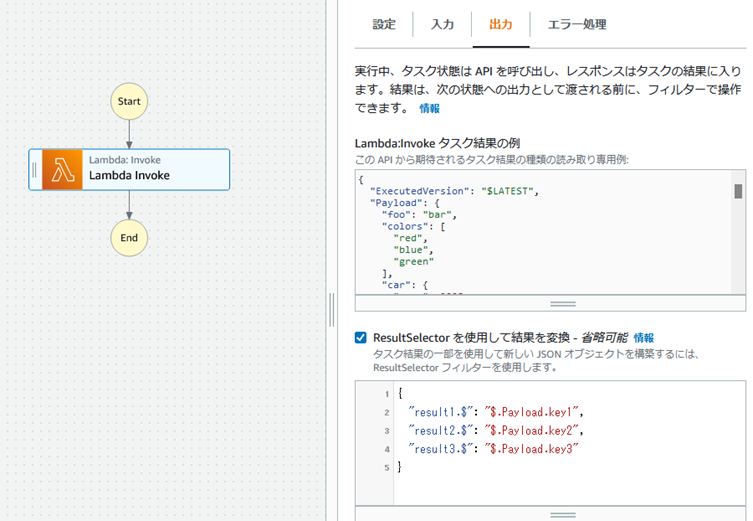
StepFunction�̎��s���ʁB
���`�������W�IS3->RDS��Step Functions�Ŏ���
S3�ɂ���JSON�t�@�C�����AStep Functions��p����RDS(Serverless Aurora��MySQL�݊�)�ɓo�^����B
�ڕW�Ƃ���\���F
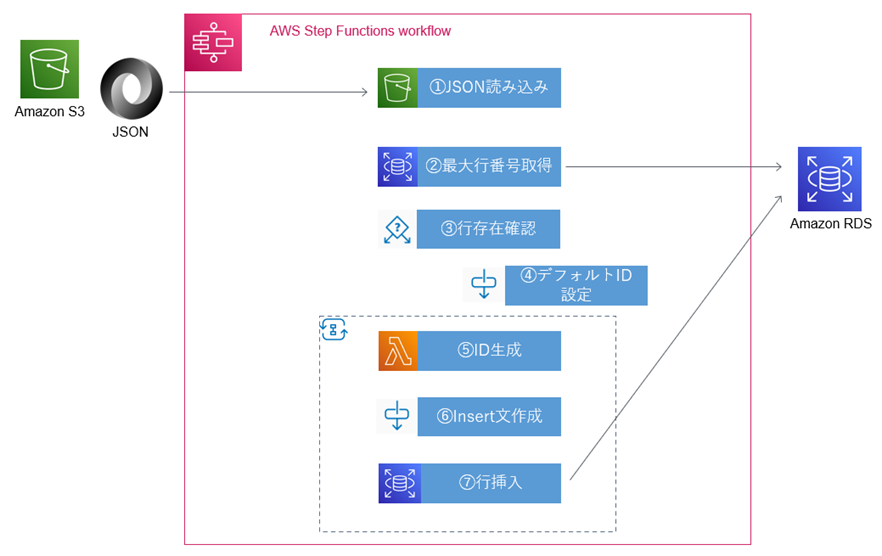
Step Functions�ł̎����͈ȉ��B
RDS�ɂ���Family�e�[�u���̒�`�͈ȉ��B
Database: golden
Table: Family
Columns:
|
id |
int(11)
PK |
|
firstname |
varchar(45) |
|
lastname |
varchar(45) |
|
age |
int(11) |
Step Functions�ɕt�^����IAM���[���̋��|���V�[�F
���ӁjServerless Aurora�ɂ�Serverless�łȂ�Aurora�̗l�ɗႦ�Z�L�����e�B�O���[�v��Aurora�̃|�[�g3306���J�����Ă����Ƃ��Ă��AVPC�̊O������p�u���b�N�A�N�Z�X�͏o���Ȃ��B
�A�N�Z�X���o����͓̂���VPC��ɂ���EC2����݂̂ƂȂ��Ă���B����ł͉����ƕs�ւȂ̂ŁA����VPC��ɂ���EC2�ݑ�ɂ��ăA�N�Z�X������@������B
MySQL Workbench�̐ݒ��F
- Standard TCP/IP over SSH
- SSH Hostname : <YOUR EC2 �p�u���b�N IP>
- SSH Username : <YOUR
username> #�悭����̂́Aubuntu, ec2-user, admin�Ȃ�
- SSH KeyFile: <YOUR EC2 .pem
file>
- MYSQL Hostname: <database�̃G���h�|�C���g>
- MYSQL Port: 3306
- Username : <database�̃��[�U��>
�@JSON�ǂݍ��݁F
S3�Ɋi�[����Ă���JSON�t�@�C����ǂݍ��ށB
Family.json
{
"family": [
{
"firstname": "John",
"lastname": "Walker",
"age": 39
},
{
"firstname": "Emily",
"lastname": "Walker",
"age": 26
},
{
"firstname": "Susan",
"lastname": "Walker",
"age": 6
},
{
"firstname": "Mike",
"lastname": "Walker",
"age": 4
}
]
}
JSON�ǂݍ��݂̉ӏ��ł̍H�v�́AS3�Ɋi�[���ꂽJSON�`���ł͂��邪������ł���t�@�C���̓��e���AStep Functions�ɗp�ӂ���Ă���g�ݍ��݊��u"States.StringToJson�v��p����JSON�I�u�W�F�N�g�Ƃ��Ď�舵����悤�ɂ����Ƃ���BS3 GetObject API�̏o�͂�ResultSelector�ɂĈȉ������{�B
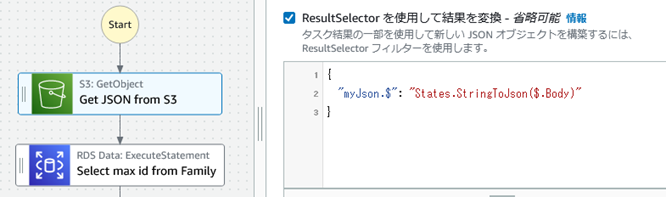
�i�Q�l�jStep Functions �g�ݍ��݊��h�L�������g�F
�iStackOverflow���e�jS3�ɂ���JSON�t�@�C������S3
API�ł���GetObject���g����Step
Functions�Ɏ�荞�ށB
�A�ő�s�ԍ��擾
RDS��Serverless Aurora�ɃA�N�Z�X���邽�߂ɂ́A�\��Secret Manager��p���ăV�[�N���b�g���쐬���Ă����AAPI�̃p�����^�ɃV�[�N���b�g��arn��n���K�v������B
�ȉ��̓V�[�N���b�g�̏����i���[�U�APW��Aurora�̃��[�U�APW�j
 ]
]
�܂�Step Functions��RDS��API���g���ɂ́AServerless
Aurora����Data API��L�����������K�v������B
�Ȃ��AServerless Aurora�����p�\��MySQL�̃o�[�W�����́i5.6.10a, 2.07.1�j�̂݁B�i2022/05/06���݁j
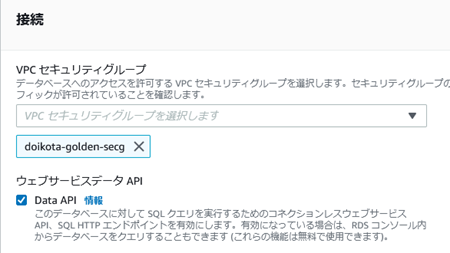

�B�s���݊m�F
Family�e�[�u����Max ID�́A�e�[�u����1�s�ȏヌ�R�[�h�����݂�����̒l�Ƃ��A�����ꍇ�̓f�t�H���g�̏������s���B
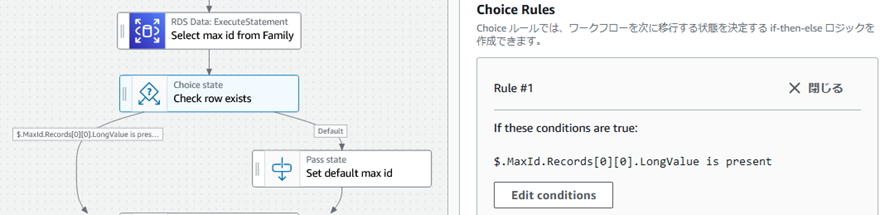
�C�f�t�H���gID�ݒ�
�s�����݂��Ȃ��ꍇ�A�X�㌻���_�ł̍ő��ID�ɂ�-1��ݒ肷��B�悭�����@���ƁB
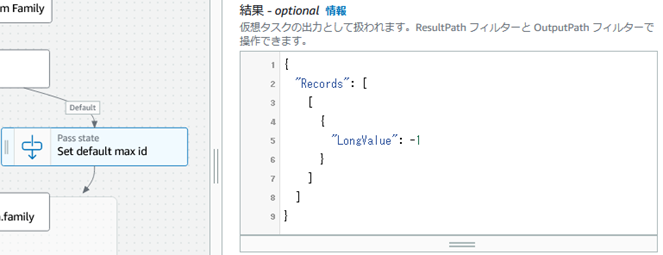
Map�����F
Map�̓��͂ŁA�㗬���痬��Ă���f�[�^�ł���Family�e�[�u����id�̍ő�l��Map�̃R���e�L�X�g�I�u�W�F�N�g��p���āAJSON�̊e�z��v�f��g�ݑւ��Č㑱�������z�����s����l�ɂ���B
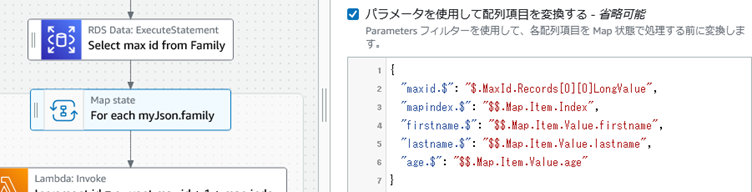
Map�X�e�[�g���L�̃R���e�L�X�g�I�u�W�F�N�g�i$$.Map.Item.Index��$$.Map.Item.Value�j���g���āA�z��̃C���f�b�N�X�Ɨv�f���擾�ł���B
�Q�l�j�}�b�v�X�e�[�g�̃R���e�L�X�g�I�u�W�F�N�g�f�[�^
�DID����
�c�O�Ȃ���Step Functions�͐��l�̌v�Z�������o���Ȃ��͗l�i2022/05/08���݁j�B
���̉ӏ��̂ݎd���Ȃ��ALambda�̃}�C�N���T�[�r�X�Ŏ�������B
lambda_function.py
import json
def lambda_handler(event,
context):
event['id'] =
event['mapindex'] + 1 + event['maxid']
return event

Lambda�����̉ӏ��́A�����ς݂�Lambda����arn����͂��Ă����B
�EInsert���쐬
�����ł�Pass�X�e�[�g�ł̓��͂�Parameters�ϊ��ɂ����āA�g�ݍ��݊�States.Format��p���ĕ��������s���B

{
"Insert.$":
"States.Format('Insert into golden.Family values ({}, \\'{}\\', \\'{}\\',
{})', $.id, $.firstname, $.lastname, $.age)"
}
����L�̐}�ł͐�Ă��邪�A���S�̂͏�f�̒ʂ�B{}���v���[�X�z���_�Ƃ��ĕ�����{}���㑱�̕ϐ��l�Œu����������B�V���O���N�H�[�g���L�q����ꍇ�ɂ́A\\'�Ƃ��ăG�X�P�[�v�����Ƃ��Ĉ����B
�F�s�}��
�����܂ŗ����炠�Ƃ͇E�ō쐬����Insert�������s����̂݁B
���Q�l�j�\�[�X�R�[�h�S��
���ӁF�M�ҌŗL�̃��\�[�X���̂�<YOUR...>�̃v���[�X�z���_�[�Ƃ����̂œK�X�����ւ����K�v�B
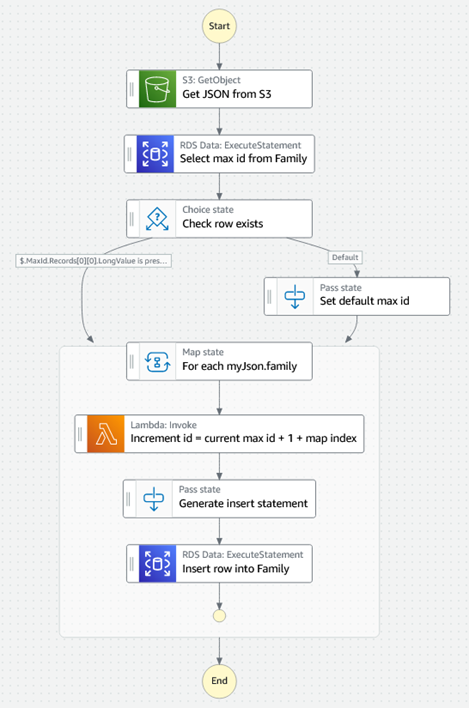
{
"StartAt": "Get JSON from
S3",
"States": {
"Get JSON from
S3": {
"Type": "Task",
"Parameters": {
"Bucket": "<YOUR S3 Bucket>",
"Key": "<YOUR S3 File>"
},
"Resource": "arn:aws:states:::aws-sdk:s3:getObject",
"ResultSelector": {
"myJson.$": "States.StringToJson($.Body)"
},
"Next": "Select max id from Family",
"Comment": "S3 -> JSON"
},
"Select max id from
Family": {
"Type": "Task",
"Parameters": {
"ResourceArn": "<YOUR RDS arn>",
"SecretArn": "<YOUR Secret arn>",
"Sql": "select max(id) from golden.Family;"
},
"Resource": "arn:aws:states:::aws-sdk:rdsdata:executeStatement",
"ResultPath": "$.MaxId",
"Next": "Check row exists"
},
"Check row
exists": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.MaxId.Records[0][0].LongValue",
"IsPresent": true,
"Next": "For each myJson.family"
}
],
"Default": "Set default max id"
},
"Set default max
id": {
"Type": "Pass",
"Next": "For each myJson.family",
"ResultPath": "$.MaxId",
"Result":
{
"Records": [
[
{
"LongValue": -1
}
]
]
}
},
"For each
myJson.family": {
"Type": "Map",
"End":
true,
"Iterator": {
"StartAt": "Increment id = current max id + 1 + map
index",
"States": {
"Increment id = current max id + 1 + map index": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"Payload.$":
"$",
"FunctionName": "<YOUR Lambda arn>"
},
"Retry": [
{
"ErrorEquals": [
"Lambda.ServiceException",
"Lambda.AWSLambdaException",
"Lambda.SdkClientException"
],
"IntervalSeconds": 2,
"MaxAttempts": 6,
"BackoffRate": 2
}
],
"Next": "Generate insert statement",
"OutputPath": "$.Payload"
},
"Generate insert statement": {
"Type": "Pass",
"Next": "Insert row into Family",
"Parameters": {
"Insert.$": "States.Format('Insert into golden.Family
values ({}, \\'{}\\', \\'{}\\', {})', $.id, $.firstname, $.lastname,
$.age)"
}
},
"Insert row into Family": {
"Type": "Task",
"End": true,
"Parameters": {
"ResourceArn": "<YOUR RDS arn>",
"SecretArn": "<YOUR Secret arn>",
"Sql.$": "$.Insert"
},
"Resource":
"arn:aws:states:::aws-sdk:rdsdata:executeStatement"
}
}
},
"MaxConcurrency":
4,
"ItemsPath": "$.myJson.family",
"ResultPath": "$.MapResult",
"Parameters": {
"maxid.$": "$.MaxId.Records[0][0].LongValue",
"mapindex.$": "$$.Map.Item.Index",
"firstname.$": "$$.Map.Item.Value.firstname",
"lastname.$": "$$.Map.Item.Value.lastname",
"age.$": "$$.Map.Item.Value.age"
}
}
},
"Comment": "S3 -> JSON
-> RDS",
"TimeoutSeconds": 30
}
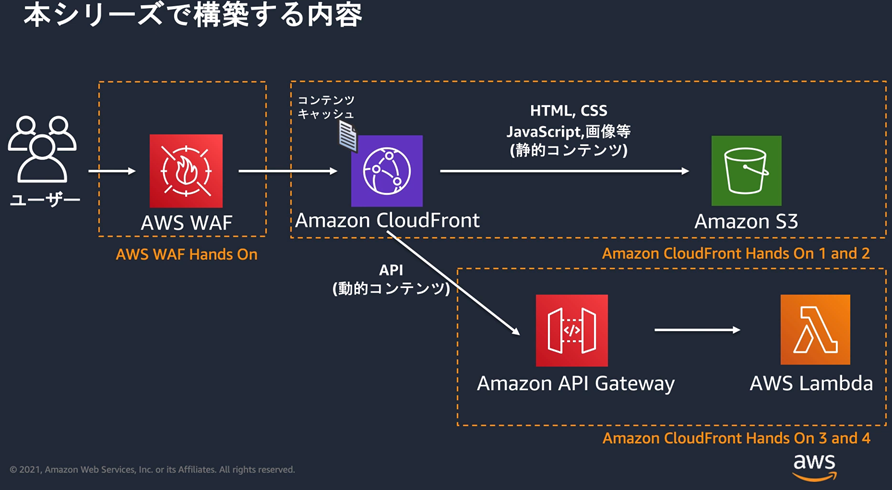
��CloudFront�AWAF���g�����G�b�W�T�[�r�X
Amazon CloudFront�����AWS WAF��p���� �G�b�W�T�[�r�X�̊��p���@���w�ڂ�
https://pages.awscloud.com/JAPAN-event-OE-Hands-on-for-Beginners-CF_WAF-2021-confirmation-343.html
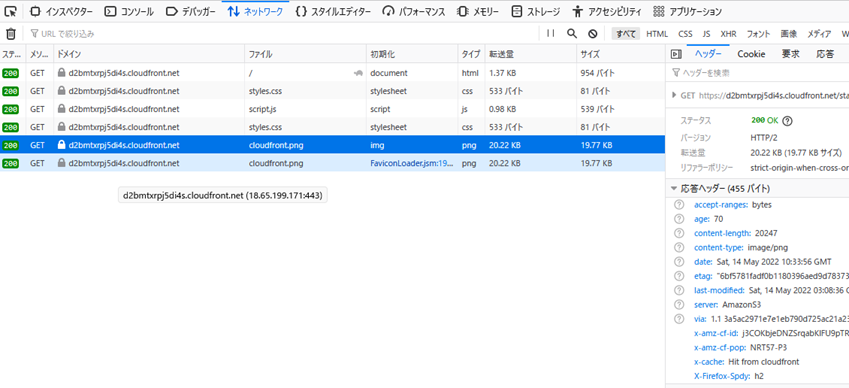
CloudFront���t�@�C�����L���b�V�����Ă��邩�i�I���W���T�[�o����t�@�C��������ė��Ă��邩�ǂ����j�̊m�F���@�F
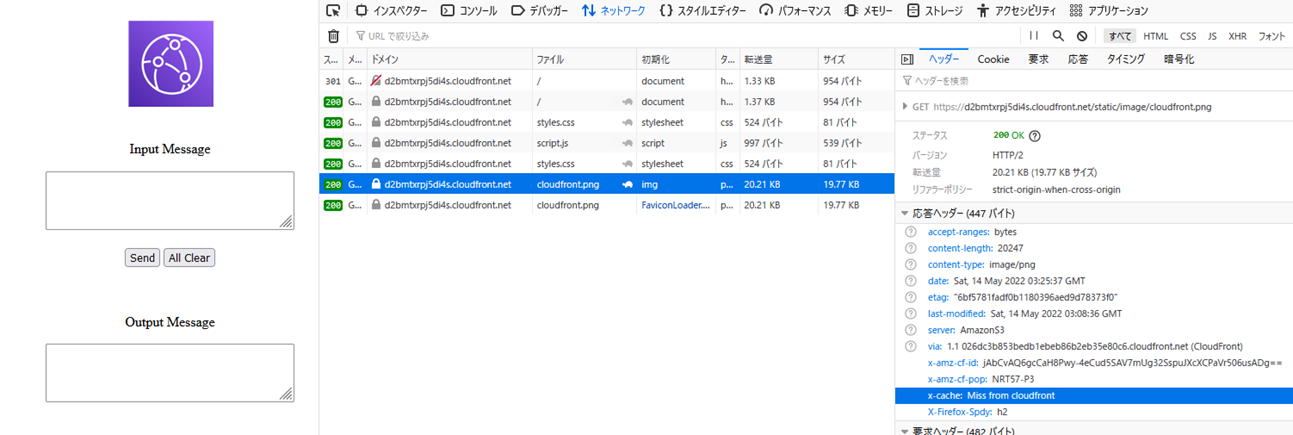
x-cache: Miss from cloudfront�ƂȂ��Ă���Acloudfront��ɑ��݂����A�I���W���T�[�o����t�@�C��������ė��Ă��邱�Ƃ�������B
�L���b�V���|���V�[��ҏW���A
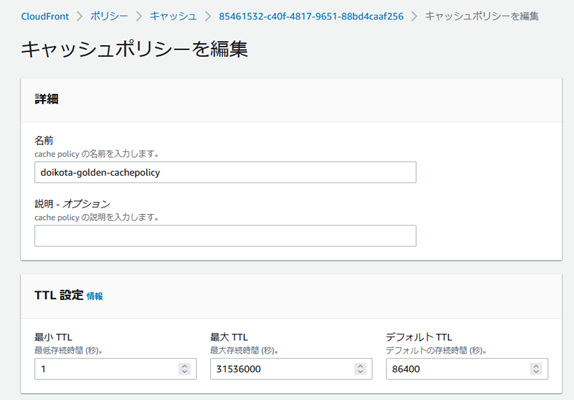
�r�w�C�r�A�̃L���b�V���|���V�[�ɒlj�����ƁA�A�A
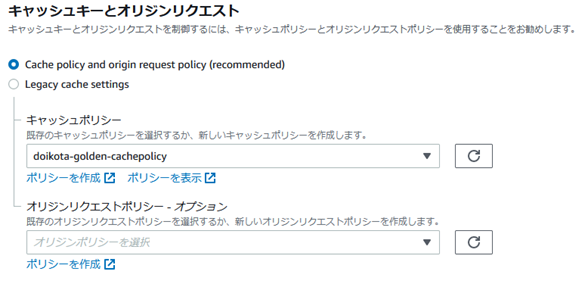
x-cache: Hit from cloudfront�ƂȂ�A�L���b�V������擾�ł���悤�ɂȂ����̂�������B
�I���W�����N�G�X�g�|���V�[�F
CloudFront�ւ̃r���[���[���N�G�X�g�ɂ��A�L���b�V���~�X�����������ꍇ�ACloudFront�̓I�u�W�F�N�g���擾���邽�߂̃��N�G�X�g���I���W���ɑ��M���邪�A����̓I���W�����N�G�X�g�ƌĂ��B
�I���W�����N�G�X�g�ɂ́A�r���[���[���N�G�X�g�̎��̏��Ɋ܂܂�܂��B
�EURL�p�X(URL�N�G��������܂��̓h���C�������܂܂Ȃ��p�X�̂�)
�E���N�G�X�g�{�f�B(���݂���ꍇ)
�ECloudFront�����ׂẴI���W�����N�G�X�g�Ɏ����I�Ɋ܂߂�HTTP�w�b�_�[(Host�AUser-Agent�AX-Amz-Cf-Id�Ȃ�)�B
�r���[���[���N�G�X�g�̂��̑��̏��(URL�N�G��������AHTTP�w�b�_�[�ACookie�Ȃ�)�́A�f�t�H���g�ł̓I���W�����N�G�X�g�Ɋ܂܂�Ȃ��B
�I���W�����N�G�X�g�|���V�[���g�p���邱�ƂŁA�I���W���ł��̂��̑��̏�����M���邱�Ƃ��ł���悤�ɂȂ�B
�I���W�����N�G�X�g�|���V�[�́A�L���b�V���L�[�𐧌䂷���L���b�V���|���V�[�Ƃ͕ʂ��́B
���̕����ɂ��A�I���W���Œlj�������M���A�ǍD�ȃL���b�V���q�b�g��(�L���b�V���q�b�g�ƂȂ�r���[���[���N�G�X�g�̊���)���ێ����邱�Ƃ��ł���B
�n���o�[�K�[���j���[�̃|���V�[����A�I���W�����N�G�X�g�|���V�[��ҏW����B
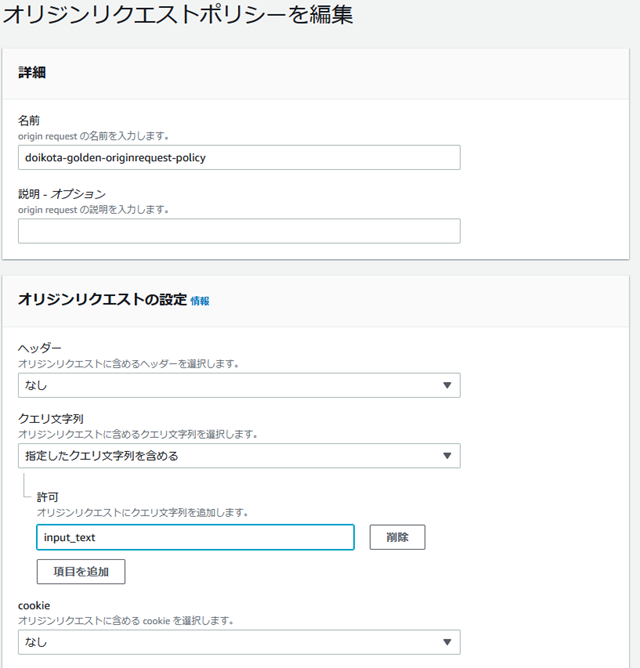
�N�G�������ɍ���I���W���ɓn�������p�����^�ł���input_text��ݒ肷��B
���I�p�����[�^�ł���N�G����������܂�API�̏����ΏۂƂ��āA�I���W����lj�����B
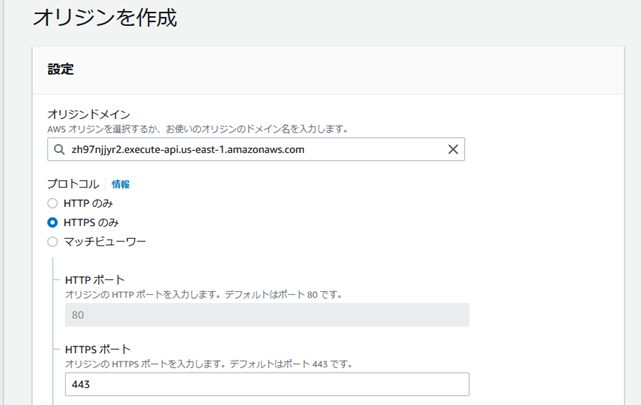
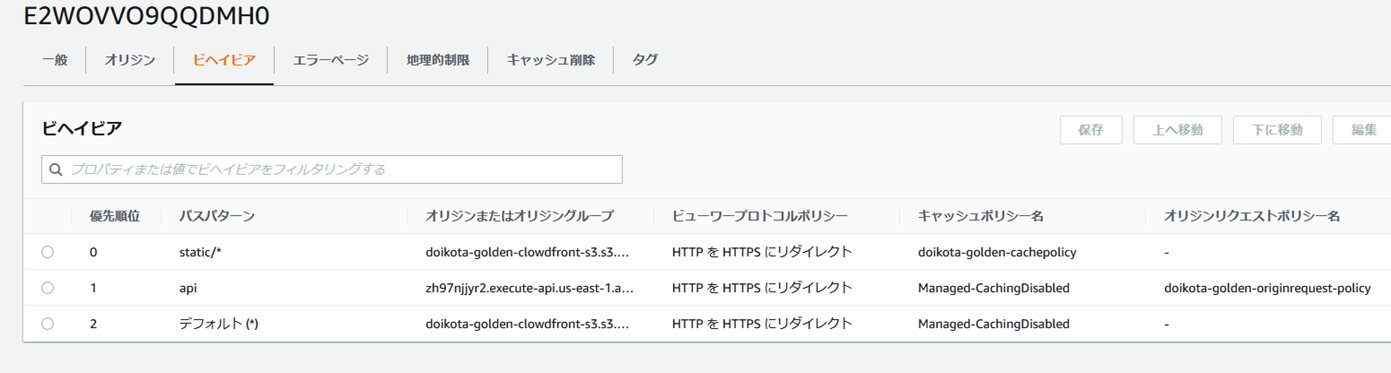
APIGateway�����̃I���W�����lj����ꂽ�B
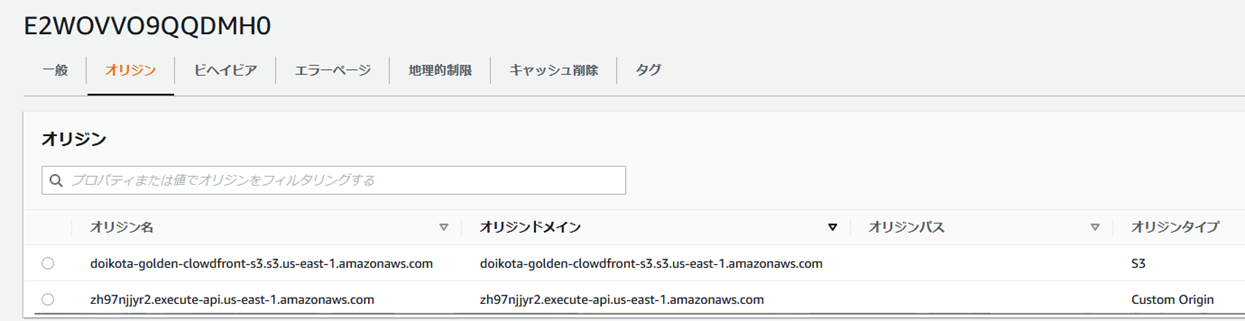
�r�w�C�r�A���V�����I���W���Ɍ������l�ɂ���B
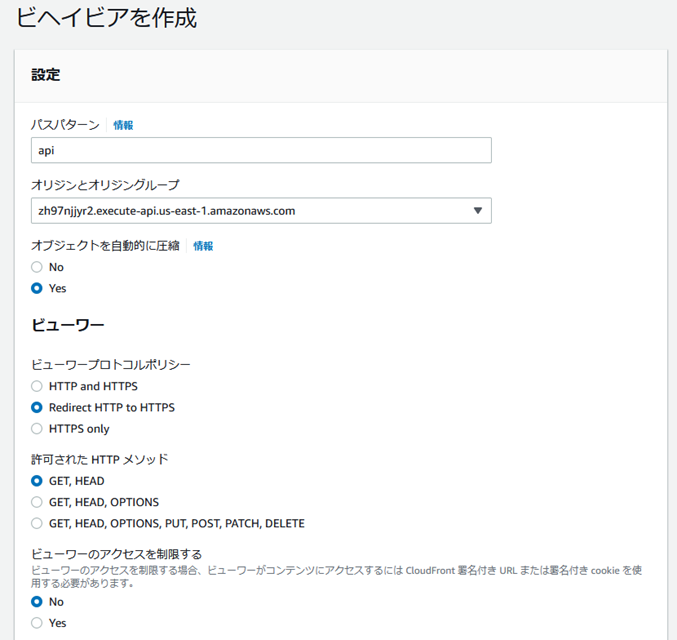
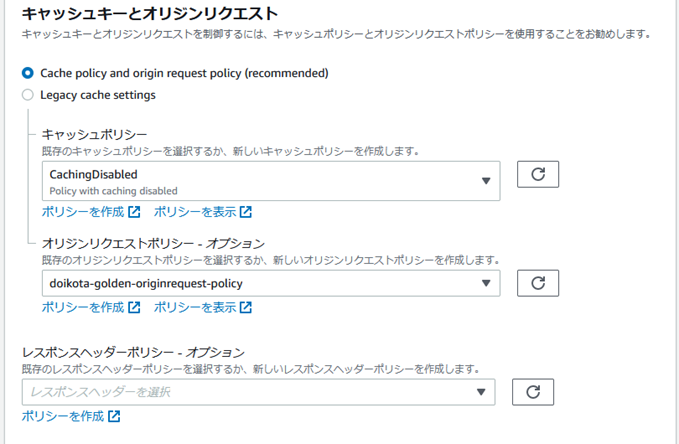
api�Ƃ����p�X�p�^�[���ɃI���W�����N�G�X�g�|���V�[��R�Â���B
AWS�@WAF�iWeb
Application Firewall�j�ɂ��ACL��Rule�̐ݒ�F
�p���A�Z�L�����e�B�N�Q�A���\�[�X�̉ߏ����ɉe����^����悤�ȁA�E�F�u�̐Ǝ㐫�𗘗p������ʓI�ȍU����{�b�g����A�E�F�u�A�v���P�[�V�����܂��� API ��ی삷��E�F�u�A�v���P�[�V�����t�@�C�A�E�H�[���B
�e��AWS�T�[�r�X��WAS��R�Â���ɂ́AWeb ACL�̒P�ʂōs���B
���ACL�̒��ɕ�����Rule��݂��邱�Ƃ��o����B
Rule�̒��ɕ�����Statement��݂��鎖���o���āAStatement��AND������OR�����őg�ݍ��킹�鎖���o����B
Statement�Ŏw�肵�������Ƀ}�b�`�����ꍇ�A�A�N�V���������s�����B
�w��ɂ��Rule�ݒ���\�ŁA�����Rate based Rule�ƌĂ��B
ACL���`���ACloudFront��R����B
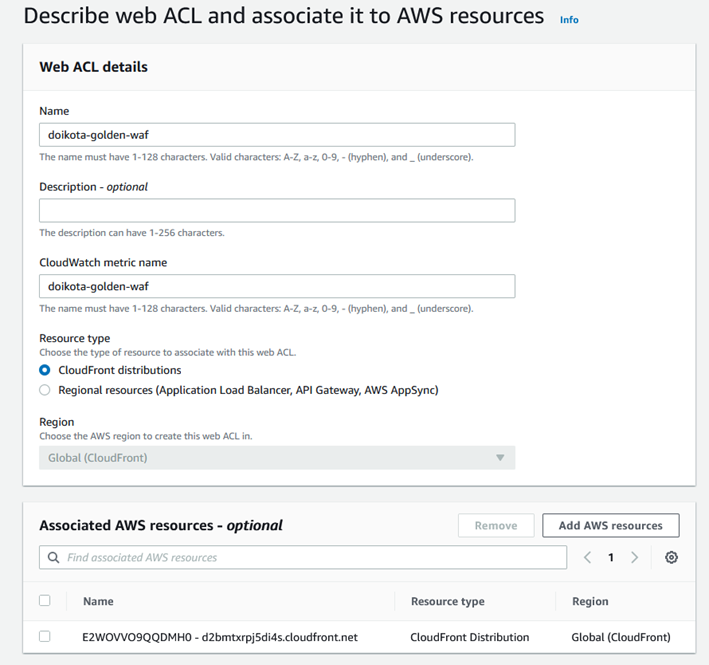
����̒n��ȊO����̃A�N�Z�X�i��F�C�O����̃A�N�Z�X�j�͋��ہiBlock�j�Ƃ�����Rule���쐬���AACL�ɓo�^����B
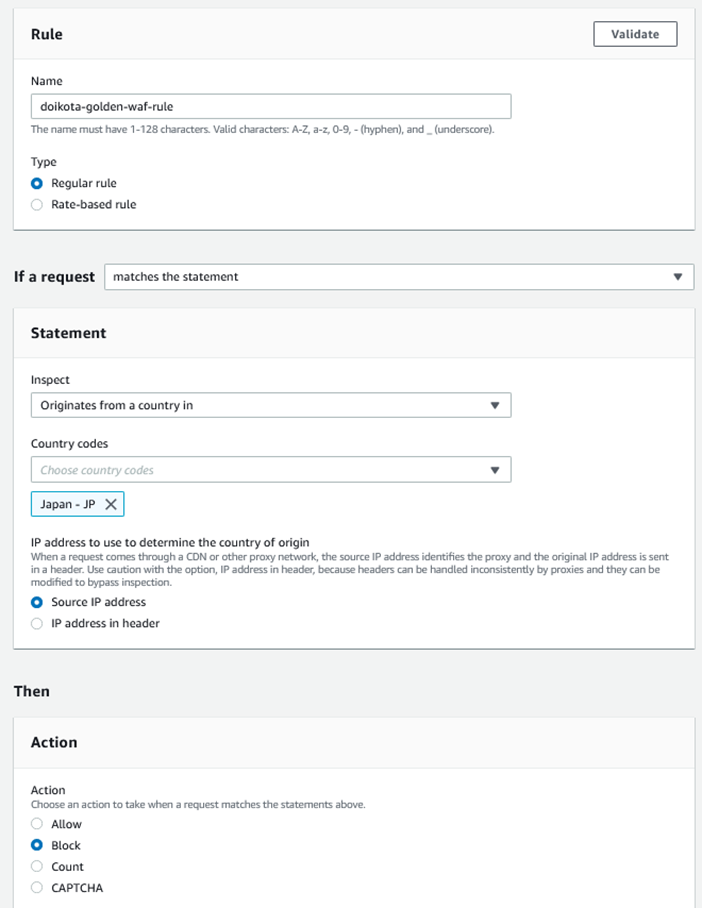
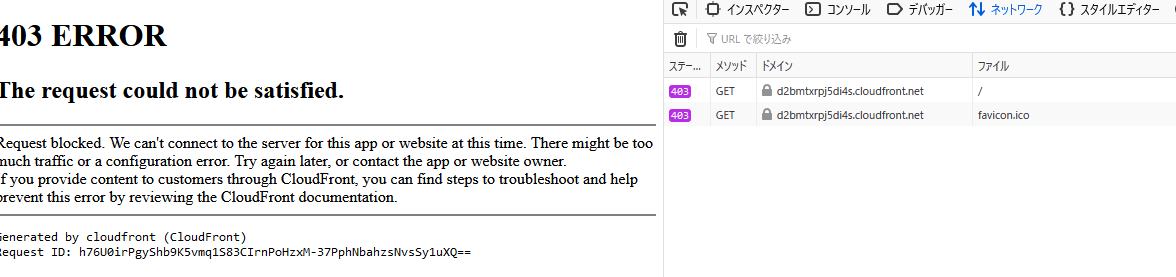
Rule�ݒ��A�A�N�Z�X�s�\�ƂȂ�B
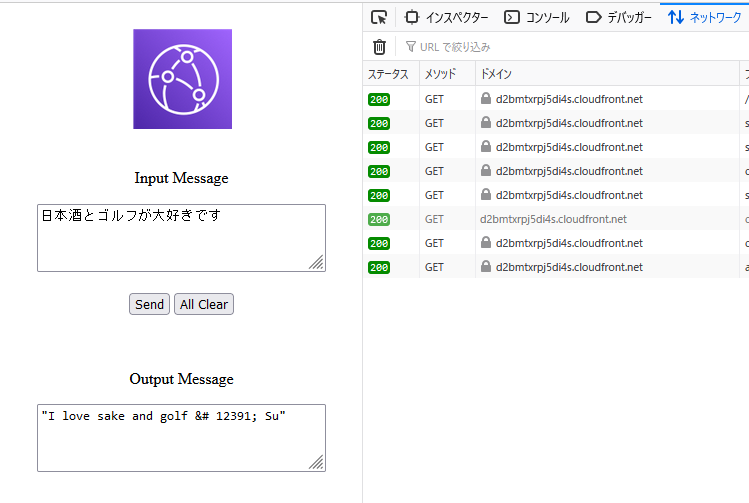
Action��Allow�ɂ���ƁA�A�N�Z�X�\�ƂȂ�B
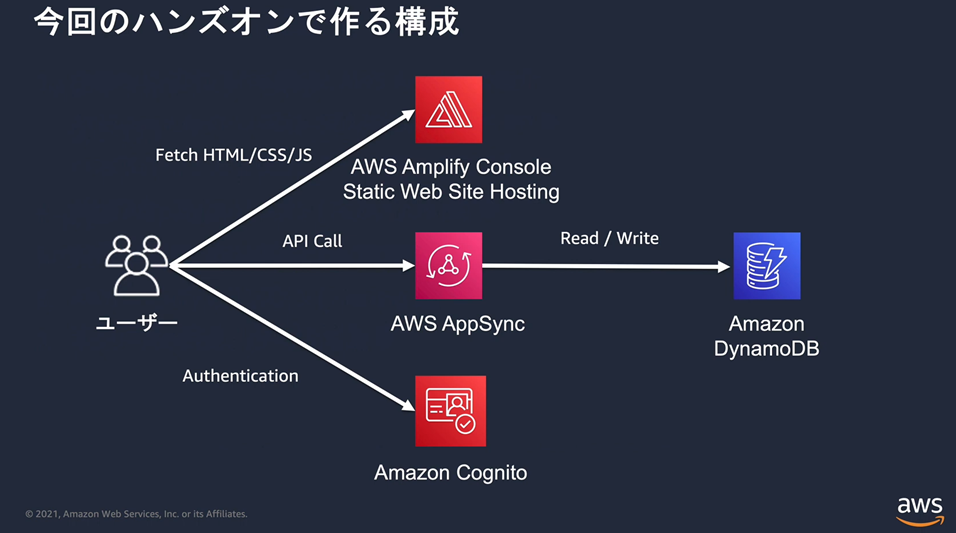
��AWS Amplify ��p���� Web �T�C�g�̍\�z���@
https://pages.awscloud.com/JAPAN-event-OE-Hands-on-for-Beginners-amplify-2022-confirmation-774.html
Amplify Docs for React�F
https://docs.amplify.aws/start/q/integration/react/
AWS Amplify�Ƃ́F
AWS��Web�e��T�[�r�X��g�ݍ��킹�A�G���h���[�U����Web�A�v���P�[�V�����̍\�z�A�����グ�������I�ɍs�����߂̃T�[�r�X�B
AWS�@Amplify�̍\���v�f�F
Ø Amplify���C�u����
Web��o�C���A�v����AWS�����邽�߂�OSS���C�u����
Ø Amplify�@CLI
Web��o�C���A�v���̃o�b�N�G���h��Θb�I�ɍ\�z���邽�߂�OSS�c�[���Q
Ø Amplify�R���\�[��
�T�[�o���XWeb�A�v�����r���h�A�e�X�g�A�f�v���C�A�z�X�e�B���O���邽�߂̃T�[�r�X
Ø Amplify�@AdminUI
Web��o�C���A�v���̃o�b�N�G���h�ƃR���e���c���Ǘ����邽�߂�GUI
Cloud9�\�z���̃|�C���g
u EC2��t3.small���w��it2.micro���ƃ������s���G���[���N�����\�������邽�߁j
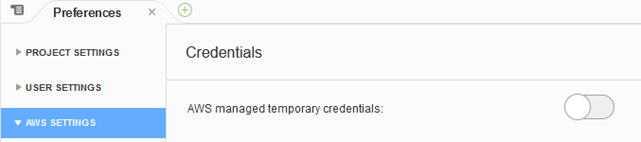
u AWS���Ǘ�����ꎞ�I�ȔF�؏���������BCloud9�R���\�[�����J���Ƃ��ɕ����o�����ꎟ�F�؏����AAmplify CLI�Ŕ��s����F�؏��ɒu�������邽�߂ɁA����������B
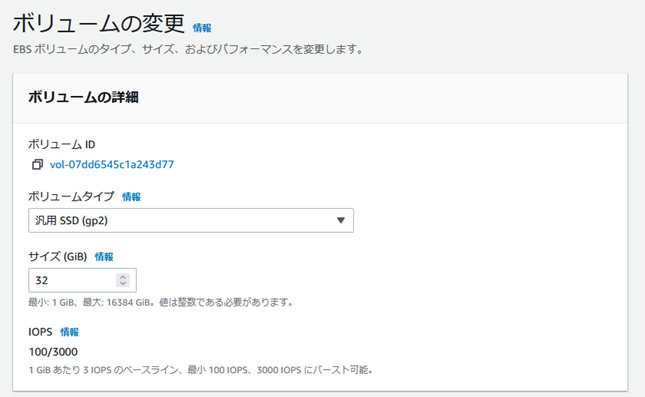
u Cloud9�̃C���X�^���X��EBS�iEC2�u���b�N�X�g���[�W�j�{�����[���������グ��B�i10->32GB�j
Amplify��ݒ肷��B
iamdoikota01:~/environment
$ npm install -g @aws-amplify/cli
added 26 packages, and
audited 27 packages in 14s
7 packages are looking
for funding
run `npm fund` for details
found 0
vulnerabilities
iamdoikota01:~/environment
$ amplify configure
Follow these steps to set
up access to your AWS account:
Sign in to your AWS
administrator account:
https://console.aws.amazon.com/
Press Enter to
continue
Specify the AWS Region
? region: ap-northeast-1
Specify the username
of the new IAM user:
? user name: amplify-0LLT1
Complete the user
creation using the AWS console
https://console.aws.amazon.com/iam/home?region=ap-northeast-1#/users$new?step=final&accessKey&userNames=amplify-0LLT1&permissionType=policies&policies=arn:aws:iam::aws:policy%2FAdministratorAccess-Amplify
Press Enter to
continue
Enter the access key
of the newly created user:
? accessKeyId: ********************
?
secretAccessKey:
****************************************
This would
update/create the AWS Profile in your local machine
? Profile Name: Amplify
Successfully set up
the new user.